
全面解讀材料腐蝕數(shù)據(jù)的十種挖掘方法
2023-06-01 14:18:31
作者:覃艷民,李辛庚等 來源:腐蝕與防護
分享至:


腐蝕是材料失效的主要途徑之一,每年因腐蝕引起的材料損傷、設備失效、安全事故導致了重大的經(jīng)濟損失甚至人身傷亡。因服役環(huán)境不同,材料的腐蝕機理、腐蝕行為規(guī)律差異很大,對腐蝕行為進行預測也異常困難。為深刻揭示環(huán)境因素對材料腐蝕作用的機理與材料腐蝕的演化規(guī)律、搜索隱藏于數(shù)據(jù)中的腐蝕信息,人們依靠信息技術和計算機技術逐步改進了材料腐蝕數(shù)據(jù)分析方法,發(fā)展了一系列腐蝕數(shù)據(jù)分析模型。 ————————»»»»
早期進行腐蝕數(shù)據(jù)研究時,腐蝕數(shù)據(jù)主要來源于掛片腐蝕試驗,試驗的時間跨度較長,腐蝕數(shù)據(jù)通常具有高維度、小樣本、多層次、高噪聲等特征,人們主要基于曲線擬合、多元線性回歸分析等傳統(tǒng)的數(shù)學分析方法,構建材料腐蝕特征參數(shù)與環(huán)境特征參數(shù)之間的數(shù)學映射關系,研究環(huán)境特征參數(shù)對材料腐蝕過程的影響,并通過腐蝕特征參數(shù)與環(huán)境特征參數(shù)之間的定量關系來預測特定環(huán)境中的腐蝕演化。 傳統(tǒng)的分析方法難以詮釋多重環(huán)境特征因素對腐蝕的耦合影響,導致基于量化關系預測的腐蝕數(shù)據(jù)在相對較寬的地域與時域范圍內出現(xiàn)較大的偏差。隨著腐蝕監(jiān)檢測技術的快速發(fā)展,腐蝕數(shù)據(jù)與部分環(huán)境因素數(shù)據(jù)實現(xiàn)了在線連續(xù)采集,并且隨著現(xiàn)代數(shù)據(jù)分析理論的發(fā)展,很多新方法被應用于腐蝕數(shù)據(jù)的挖掘和分析,如神經(jīng)網(wǎng)絡、決策樹、隨機森林、聚類分析、圖像處理等,在處理復雜環(huán)境中的腐蝕分析與預測時,這些模型取得了長足的進步。 隨著多維度腐蝕大數(shù)據(jù)的積累,基于多種算法的集成算法被引入腐蝕數(shù)據(jù)挖掘的機器學習模型中,集成算法可以更好地滿足腐蝕數(shù)據(jù)形式多樣化的需求,并提升預測結果的準確度。
1
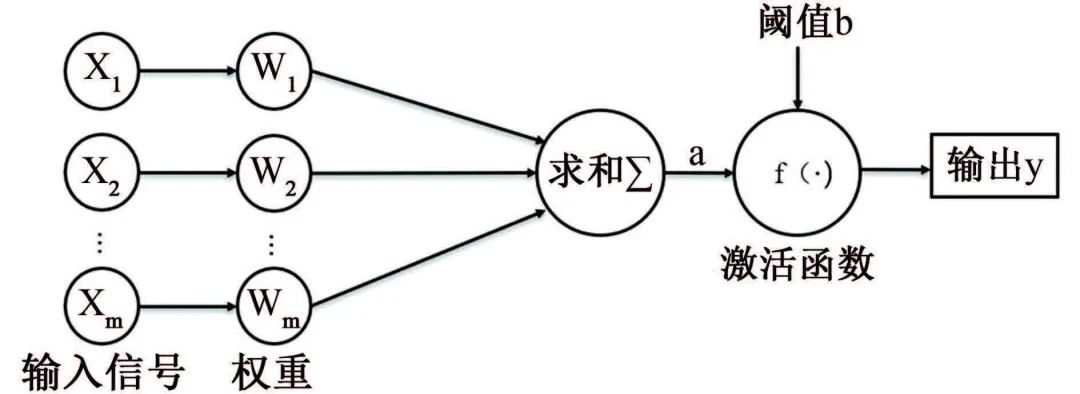
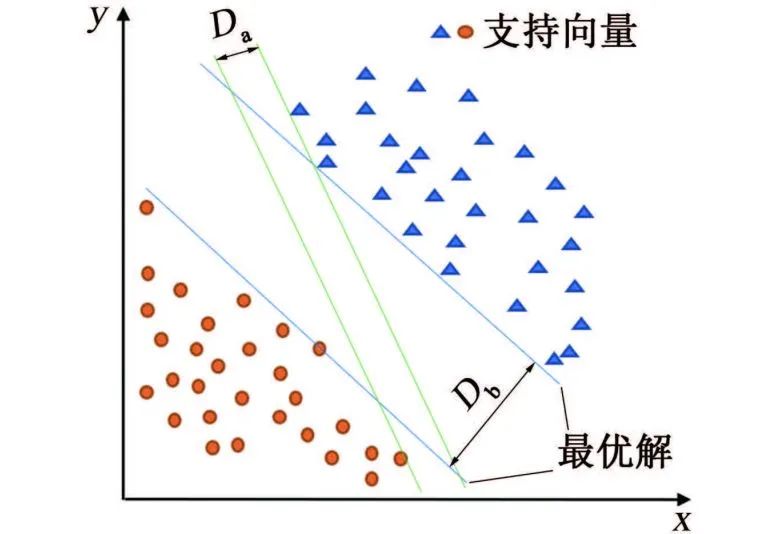
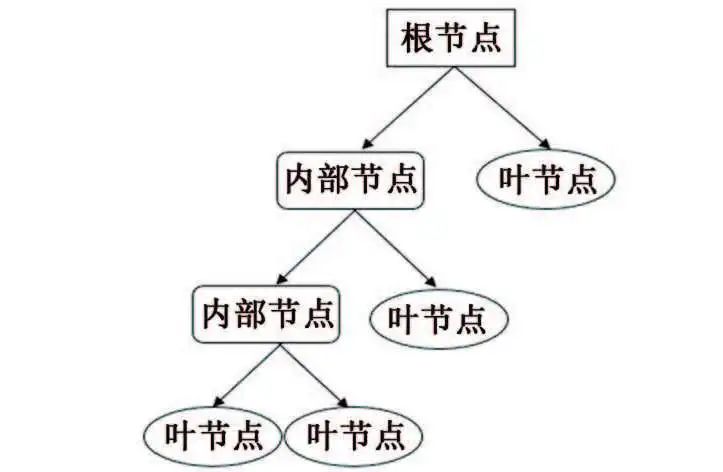
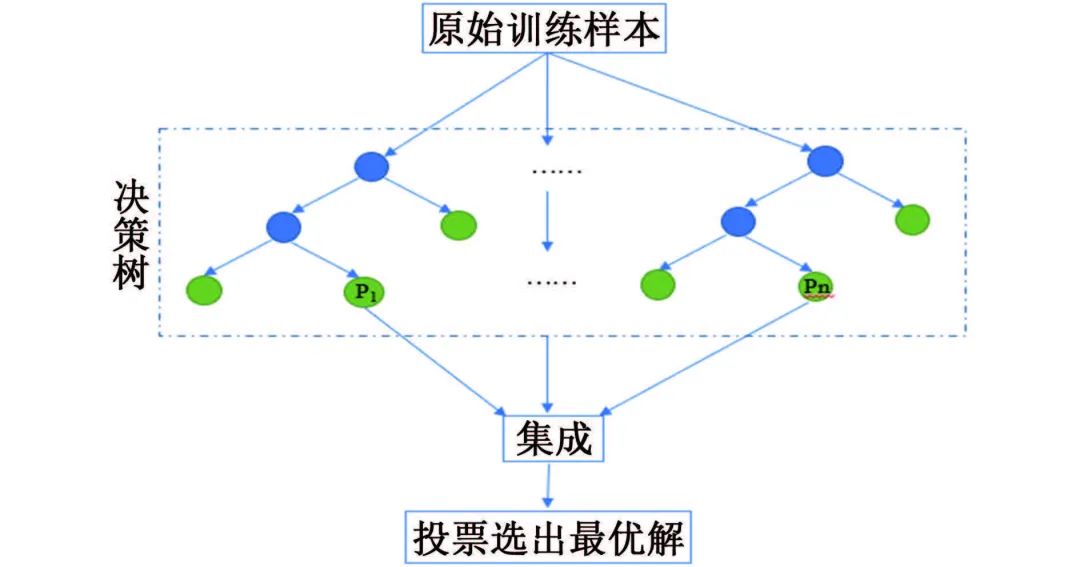
數(shù)據(jù)挖掘方法 ? 數(shù)據(jù)挖掘興起于1989年,狹義來說是“數(shù)據(jù)庫知識發(fā)現(xiàn)”(KDD)中的一個分析步驟。廣義來說,由于KDD各個環(huán)節(jié)緊密相連,各環(huán)節(jié)對數(shù)據(jù)挖掘結果影響很大,數(shù)據(jù)挖掘往往包含KDD全過程。 如圖1所示,KDD是使用統(tǒng)計學、機器學習、數(shù)學或人工智能技術等方法從給定數(shù)據(jù)集中提取有意義數(shù)據(jù)的過程,可以理解為對大量數(shù)據(jù)進行分析,以獲取潛在有用信息的過程,其技術主要包括:數(shù)據(jù)的分組、預測、數(shù)據(jù)的異常記錄、數(shù)據(jù)間的關聯(lián)法則、序列模式的發(fā)現(xiàn)等。 圖1 KDD流程圖 材料腐蝕研究是一項嚴重依賴數(shù)據(jù)的研究,人類自研究腐蝕行為開始,就非常重視腐蝕數(shù)據(jù)的獲取和積累,并試圖從中發(fā)現(xiàn)或驗證相關規(guī)律。科學家將腐蝕研究與快速發(fā)展的信息科技相結合,形成的材料腐蝕信息學促進了材料腐蝕學的快速發(fā)展,為腐蝕分析提供了更多的可能與方法。 2015年,李曉剛等首次提出了“腐蝕大數(shù)據(jù)”的概念,更加完善了腐蝕信息學的內涵。如何在腐蝕研究中合理利用數(shù)據(jù),選擇合適的數(shù)學挖掘方法和信息化手段成為了材料腐蝕研究的熱點之一。 01 多元線性回歸方程模型 多元線性回歸方程模型被廣泛應用于腐蝕預測的研究中,也是最早用于預測環(huán)境對材料腐蝕影響的數(shù)據(jù)挖掘方法。 該方法可以自動從眾多變量中選擇重要變量并建立回歸方程,排除對輸出變量影響不顯著的變量,形成最優(yōu)“方程”。研究者通常將監(jiān)測的氣象因子(相對濕度、溫度、降水、日照等)和污染物因子(SO2、Cl-、NOx、NH3等)作為一系列的變量與相應的腐蝕率進行回歸分析。 早在1960年,日本一研究小組就在日本境內的七個地方開啟了為期5年的大氣曝曬試驗,利用多元線性分析方法處理了曝曬數(shù)據(jù)與大氣環(huán)境數(shù)據(jù),得到了碳鋼的腐蝕速率方程;之后該小組還匯編了日本43個地區(qū)的暴露試驗數(shù)據(jù),分析得到了碳鋼在內陸工業(yè)大氣以及海洋大氣環(huán)境中的腐蝕速率。 PRIETO等根據(jù)數(shù)據(jù)庫收集的650多條粘合測試結果,構建了一個多元線性回歸方程以評估腐蝕和未腐蝕鋼筋的結合強度,確保鋼筋混凝土構件的結構安全性。 由于僅研究環(huán)境數(shù)據(jù)具有很大的局限性,研究人員通過人工改變外界條件來進行腐蝕研究。王海杰等通過改變土壤中NaCl含量,對比分析了NaCl污染土中含氣率、電阻率等,建立了Q235鋼在污染土中的腐蝕質量損失率線性回歸模型;廖柯喜等提出了L360管道在不同H2S分壓、CO2分壓、溫度以及流速下的腐蝕速率預測線性回歸模型。 線性回歸方程對數(shù)據(jù)量要求不高,且能清晰表示因變量與各變量間的關系,但對數(shù)據(jù)本身的線性要求太高,因此使用范圍有限。 02 曲線擬合方法 曲線擬合方法是預測材料腐蝕損失的常用模型。它是一種利用解析表達式逼近離散數(shù)據(jù)的方法,依據(jù)腐蝕規(guī)律建立函數(shù),并利用試驗數(shù)據(jù)對函數(shù)中的參數(shù)進行估計。由于并非每個變量之間都有嚴格的線性數(shù)學關系,對于復雜的非線性數(shù)據(jù),可以采用通用而又簡便的曲線進行擬合。 該方法利用連續(xù)散點圖近似刻畫數(shù)據(jù),根據(jù)曲線類型,確定相應的解析表達式,建立函數(shù)模型,如利用冪函數(shù)模型,對數(shù)函數(shù)模型等。由于它具有精度高、適用范圍廣,通用性強的特點,一般情況下,選用最小二乘算法擬合,依照殘差平方和最小的原則。 早在1975年,武鋼鋼鐵研究所聯(lián)合武漢大學數(shù)學系就利用最小二乘法原理嘗試求得腐蝕回歸方程,但數(shù)據(jù)量較少,影響了回歸式的精確度。 曹楚南利用高斯-牛頓曲線擬合法對腐蝕金屬的弱極化曲線進行擬合,估算了腐蝕過程電化學動力學參數(shù),但這種方法在處理多參數(shù)情況時,容易出現(xiàn)不收斂的情況,為改善此情況,易忠勝等利用單純形法優(yōu)化擬合,提高了計算精度及收斂性。孫峰等提出基于粒子群-信賴域的極化曲線擬合算法,解決了擬合精度不高和結果陷入局部最優(yōu)的問題。 除了以上典型模型外,韓慶華等基于三參數(shù)威布爾分布對鑄鋼及對接焊縫的腐蝕疲勞應力-壽命曲線進行修正,使該曲線具有更好的彎曲形狀且提高了擬合精度;GAZENBILLER等發(fā)現(xiàn)在105~110 ℃下,AA-1050鋁合金在無水乙醇溫度誘導化學腐蝕試驗中,最大腐蝕深度符合Gumbel統(tǒng)計規(guī)律,提出了醇類腐蝕機理。 相較于線性回歸,曲線擬合在局限方面有了一定的進步,它不要求曲線通過所有已知點,得到近似曲線即可,但在擬合曲線前,需要先分析是曲線類型,這是一個困難的過程。 03 灰色關聯(lián)分析和灰色預測 鄧聚龍?zhí)岢隽嘶疑到y(tǒng)理論,包括了灰色建模、灰色預測、灰色關聯(lián)分析等,是一種適用于分析數(shù)量少且信息貧乏的系統(tǒng)。灰色系統(tǒng)是部分信息已知而部分信息未知的系統(tǒng),灰色系統(tǒng)理論就是提取部分已知信息中有價值的信息并進行相關性推演和預測。 常用灰色關聯(lián)分析法來分析各腐蝕因素(如溫度、濕度、降雨量等)對腐蝕速率的影響程度,對腐蝕因素進行強弱排序,尋找關鍵因素。 FU等利用灰色關聯(lián)分析對影響油管的相關因素進行分析,發(fā)現(xiàn)造成油管腐蝕的主要因素是無硫腐蝕和油管中氣體的腐蝕;CAO等在中國7個典型試驗場進行為期1年的Q235鋼腐蝕試驗,采用灰色關聯(lián)分析,將影響Q235鋼的腐蝕因素進行排序,確定相對濕度是對Q235鋼腐蝕影響最嚴重的因素;鄧志安等對管線腐蝕速率與環(huán)境因素進行灰色關聯(lián)分析,選取關聯(lián)度較高的影響因素進行后續(xù)預測分析,降低了預測難度;WANG等研究了2Cr13不銹鋼在模擬深海環(huán)境中的點蝕行為,通過灰色關聯(lián)度計算,確定了各因素對不銹鋼蝕坑深度的影響由大到小依次為:靜水壓力>溶解氧含量>溫度,即在深海環(huán)境中,靜水壓力對碳鋼蝕坑深度的影響最大。 然而該方法分配權重時主觀性太強,會對計算結果產生客觀影響,而且只能反映測試條件下的腐蝕因素對腐蝕速率的影響,無法做到普遍情況下的腐蝕情況推廣。 灰色預測中GM(1,1)模型是描述灰色系統(tǒng)的最簡單模型,在計算時只需要3~7條時序性數(shù)據(jù)即可進行挖掘,建模,預測腐蝕相關因素隨時間的變化。但是,該模型在遇到隨機性數(shù)據(jù)和進行中長期預測時,擬合效果不佳,可能會降低模型預測結果的準確度。 唐其環(huán)等應用灰色GM(1,1)模型對江津地區(qū)大氣腐蝕結果進行了預測,但用于長期大氣腐蝕預測時誤差仍然較大;陳建設等基于熱鍍鋅層在海水中的腐蝕規(guī)律建立了GM(1,1)模型,將整個腐蝕過程分為三段處理,使模型具有良好的擬合和預測精度;WANG等采用GM(1,1)模型預測了回火處理后的低合金鋼在酸性溶液中的腐蝕速率,ZHANG等根據(jù)GM(1,1)模型推導了瀝青路面性能的預測方程,以有效預測高速公路瀝青路面的性能和腐蝕問題,結果表明該模型可行且能較好地用于腐蝕速率預測。 04 人工神經(jīng)網(wǎng)絡 人工神經(jīng)網(wǎng)絡(ANN)是模擬生物神經(jīng)系統(tǒng)進行信息處理,由大量人工神經(jīng)元相互連接而成的一個多輸入、單輸出的非線性元件。人工神經(jīng)元是人工神經(jīng)網(wǎng)絡操作的基本單位,每個神經(jīng)元都作為神經(jīng)網(wǎng)絡結構中一個節(jié)點,當人工神經(jīng)元的加權和輸入超過閾值時,就產生了神經(jīng)輸出,如圖2所示。 圖2 神經(jīng)元模型 人工神經(jīng)網(wǎng)絡模型種類數(shù)量繁多,如BP神經(jīng)網(wǎng)絡、HOPFIELD網(wǎng)絡、BERTYMEN模型、ART模型等,目前最常用的是由RUMELHART等提出的人工神經(jīng)網(wǎng)絡模型——反向傳播(BP)神經(jīng)網(wǎng)絡,也是腐蝕研究中應用最廣泛的網(wǎng)絡學習方法。 神經(jīng)網(wǎng)絡以試驗數(shù)據(jù)為基礎,無需事先給定公式,經(jīng)過有限次迭代后,可獲得內在規(guī)律,因此神經(jīng)網(wǎng)絡技術適用于研究腐蝕系統(tǒng)的特征問題。 郭稚弧等嘗試利用神經(jīng)網(wǎng)絡預測碳鋼在土壤腐蝕中的腐蝕速率,證實了神經(jīng)網(wǎng)絡用于土壤腐蝕規(guī)律研究的可行性;DIZA等在研究碳鋼損傷時,將濕度、SO2沉積量、降水、相對濕度(低于40%)、氯化物沉積量等作為神經(jīng)網(wǎng)絡的輸入變量,與傳統(tǒng)線性回歸相比,神經(jīng)網(wǎng)絡能預測不同氣候和污染條件下的碳鋼損傷,有更好的預測性和置信區(qū)間;劉靜等利用神經(jīng)網(wǎng)絡模型對316L不銹鋼的臨界點蝕溫度(CPT)進行預測,預測結果與試驗高度值吻合,能實現(xiàn)氣田作業(yè)區(qū)耦合環(huán)境中的CPT的預測;LI等建立了三層BP神經(jīng)網(wǎng)絡模型,預測了碳鋼在混合MDEA溶液中的腐蝕速率,輸入層有5個輸入變量,與擁有8個輸入變量的支持向量機模型(SVM)相比,該模型更優(yōu)。 然而,運用神經(jīng)網(wǎng)絡進行預測時,需要大量數(shù)據(jù)進行訓練學習,否則容易造成過擬合。 05 支持向量機 支持向量機(SVM)是由VAPNIK等提出的,基于結構風險最小化原理和統(tǒng)計學習理論的一種有監(jiān)督的新型學習方式。最初用來解決二分類問題,后來逐漸可以用于解決分類識別、小樣本回歸分析、密度函數(shù)估計等問題。 其核心是用直線將具有代表性的兩部分數(shù)據(jù)盡可能分離,這些直線稱為分隔超平面,在支持向量機理論中,需要找到這樣一個直線即超平面進行分隔,但實際上會得到多組直線,此時通過直線的最大化可移動距離來確定最優(yōu)解,在線性回歸問題中,它將求解問題轉化成了二次規(guī)劃問題。如圖3所示,Da<Db,可得最優(yōu)解。 圖3 支持向量的示意圖 支持向量機在腐蝕預測中因具有優(yōu)異的高維非線性數(shù)據(jù)處理能力,成為腐蝕數(shù)據(jù)挖掘中的常用方法。由于該方法是借助二次規(guī)劃求解支持向量,因此在涉及大量數(shù)據(jù)、高階矩陣計算時,將消耗大量內存和時間。 王大勛等引入支持向量機算法,研究了油田注水管道的腐蝕速率預測模型,提供了一種新的注水管道腐蝕預測方法;FU等將SVM算法用于大氣腐蝕研究,利用小樣本數(shù)據(jù)建立腐蝕速率預測模型,揭示了SVM算法在小樣本問題中的優(yōu)越性;周澄等在研究管道彎曲處腐蝕損傷程度智能辨識時,建立了支持向量機模型和BP神經(jīng)網(wǎng)絡模型來,對比研究了兩種模型對彎管腐蝕損傷的辨識,結果表明,支持向量機在小樣本條件下,相較于BP神經(jīng)網(wǎng)絡有更好的辨識效果。 06 貝葉斯網(wǎng)絡 貝葉斯網(wǎng)絡是基于貝葉斯理論發(fā)展而來的一種概率推理的圖形化概率網(wǎng)絡,于1988年由Judea Pearl提出,當時主要用來處理人工智能中的不確定信息。由于貝葉斯網(wǎng)絡能夠將知識經(jīng)驗融入網(wǎng)絡節(jié)點,用節(jié)點變量表達各個信息要素,用連接節(jié)點間的有向邊,表達各要素間的關系,且能處理不完整數(shù)據(jù)集,因此應用廣泛。在腐蝕領域,貝葉斯網(wǎng)絡則是側重于描述變量間的因果關系。 胡明等在分析某天然氣管道腐蝕因素時,利用貝葉斯網(wǎng)絡分析原理,將確定的23個腐蝕失效因素作為貝葉斯網(wǎng)格的子節(jié)點,管線腐蝕失效作為根節(jié)點,通過各子節(jié)點間條件概率關系,得出子節(jié)點與根節(jié)點間的概率統(tǒng)計關系,從而來指導天然氣管道系統(tǒng)的維護和維修;左哲研究了長輸管道泄漏及蒸氣云爆炸事故的演化規(guī)律,對埋地管線發(fā)生泄漏的四個階段進行了分析,構建了貝葉斯網(wǎng)絡模型,證明貝葉斯網(wǎng)絡在描述事故過程中間節(jié)點事件間依賴關系時有較大優(yōu)勢;GUO等在研究腐蝕坑形態(tài)和尺寸與應力集中系數(shù)之間的關系時,提出了應力集中貝葉斯預測模型,利用腐蝕坑的寬深比和長寬比來評價應力集中體系,預測結果有較高的準確性。 07 梯度提升決策樹 決策樹是一種基于樹形結構的應用廣泛的分類與回歸方法,如圖4所示。 圖4 決策樹示意圖 決策樹通常分為:特征選擇、決策樹的生長、以及剪枝。通過對訓練集進行學習,以樹形樣式將數(shù)據(jù)決策與數(shù)據(jù)分類過程清晰呈現(xiàn),這種算法相對簡單、直觀,具有較好的魯棒性。但是單棵樹依舊不穩(wěn)定,隨著決策樹的生長和樣本量的不斷減小深入,樣本對總體的代表性不斷減小,一般性越來越差,細微的數(shù)據(jù)變化極有可能得到完全不同的結果,且即使剪枝也易發(fā)生過擬合現(xiàn)象。 梯度提升決策樹是基于梯度提升框架的改良決策樹算法,也是近年來最有效的方法之一,通過每次迭代,在減少殘差的方向上建立了一顆新的決策樹模型,并通過各級新的決策樹加權構成新的決策樹模型。相較于單棵決策樹,梯度提升決策樹擁有更好的健壯性及泛化性,有效提高了分類及預測結果的準確性。 李秋實將梯度提升決策樹模型應用在電化學噪聲處理的腐蝕類型判別,對混合兩種數(shù)據(jù)樣本的腐蝕類型進行判別,準確性高達98.4%,且擁有傳統(tǒng)腐蝕類型判別方法所無法實現(xiàn)的普適性。梁喜旺等則利用梯度提升樹建立了大氣腐蝕預測模型,與單棵回歸樹相比,預測效果誤差降低了近一半。 08 隨機森林 隨機森林是由BREIMAN在2001年提出的一種統(tǒng)計學習理論,通過集成學習思想將多個弱分類器的決策樹模型組成一個強分類器,其建模過程就是多個樹模型的學習過程,如圖5所示。 圖5 隨機森林模型示意圖 隨機森林模型改善了單棵決策樹在小樣本處理中出現(xiàn)的過擬合現(xiàn)象,具有易于實現(xiàn)、魯棒性、可解釋性好、穩(wěn)定、適合處理高維數(shù)據(jù)、不受噪聲影響等優(yōu)點,是一種自然的非線性建模工具,因此隨機森林模型在生物、農業(yè)、醫(yī)學、風險評價等領域都有廣泛的應用。從2016年起,隨機森林就開始被運用在腐蝕領域。 MORIZET等將隨機森林與k-最近鄰算法進行了比較,后將隨機森林與小波分析進行結合,提出了一種分離局部腐蝕信號的新方法;HOU等采用電化學噪聲法研究碳鋼在保溫礦棉下腐蝕性能,并用隨機森林模型來識別腐蝕類型;YAN等將鋼的化學成分和環(huán)境因素映射到相應環(huán)境條件下低合金鋼的腐蝕速率中,建立了隨機森林模型,實現(xiàn)了準確的腐蝕速率預測,且得出環(huán)境腐蝕性的決定因素為空氣中Cl-的沉積速率。此外,還論證了隨機森林模型、CART回歸樹、RF隨機森林三種方法對新環(huán)境中鋼樣的腐蝕預測能力,結果表明隨機森林模型的預測能力優(yōu)于其他模型。 09 聚類分析 聚類是一種無監(jiān)督學習模式,常用來尋找數(shù)據(jù)之間內在結構關聯(lián)性與差異性。它通過一定規(guī)則的數(shù)據(jù)集劃分為相似的若干個類,認為兩個目標間距離越近,相似度越大,這些相似組被稱為簇,要保證每個簇中數(shù)據(jù)具有相似性,不同簇之間具有差異性,可通過歸并每一簇間的特性來概括整個數(shù)據(jù)集或者用作其他模型的輸入。 在腐蝕領域,影響腐蝕的因素復雜多樣,常采用該方法對各因素進行聚類分析從而評估各影響因素。朱超慧在研究影響高含硫管道腐蝕因子間關系時,采用了因子分析、相關分析和聚類分析三種方法,聚類分析從整體出發(fā)對整個樣本進行合理的分類,增加了數(shù)據(jù)分析的合理性;張騰等基于系統(tǒng)聚類方法,根據(jù)大氣腐蝕的差異性,將17個典型地區(qū)進行了分類,確定了我國大氣腐蝕分區(qū)個數(shù)和各區(qū)的劃分標準;周健科等對配電網(wǎng)引流線進行聚類分析,提取了海島微氣象環(huán)境中的空間故障規(guī)律,劃分失效評估區(qū)域,有效提升引流線失效評估模型準確性。 10 模糊理論 模糊集是L.A.Zadeh于1965年提出的概念,最初用來解決控制領域的疑難,后來隨著模糊邏輯和模糊理論等的發(fā)展,模糊集方法也被用于數(shù)據(jù)挖掘的分類和回歸任務中。 模糊理論針對原本無法歸入集合的模糊數(shù)據(jù),將經(jīng)典集合的外延模糊,使這些具有模糊屬性的對象歸入模糊集合,能夠被量化統(tǒng)計。模糊集合和模糊邏輯的定義合理反映了現(xiàn)實世界數(shù)據(jù)間的關系,可以改善模型的預測性能,對模糊規(guī)則的應用可以提高模型的可解釋性。 安新正等基于模糊理論建立了高橋墩工作性能損傷模糊綜合評價方法,采用此法對某鋼筋混凝土高橋墩的工作性能進行評價,結果與現(xiàn)場調查的工況基本一致;雷云等利用模糊理論處理經(jīng)專家評估的影響海底管道失效的各風險因素后,利用軟件進行計算,進行模糊綜合評估,結果表明在役管道的風險等級較低,并確定海底管道失效的主要原因,這些也與事故統(tǒng)計結果基本一致。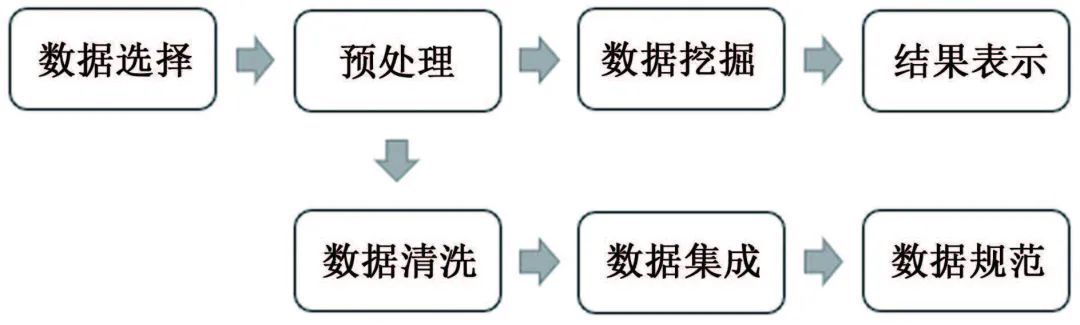
2
腐蝕中集成算法的應用 ? 傳統(tǒng)的方法是在一個可能的函數(shù)構成的空間中尋找一個最接近實際模型的預測器,例如上述提到的多元線性回歸、人工神經(jīng)網(wǎng)絡、貝葉斯網(wǎng)絡等等。近年來,傳統(tǒng)的單一模型往往精度不高,且容易出現(xiàn)過擬合問題。因此,國內外學者將目光轉向通過集成多個算法模型來進行預測和分類,改善單一模型帶來的弊端。集成學習通過組合多種弱分類器,將對應不同特征能力的模型有效結合起來,得到了一個強學習器,從而提升了模型的精確度。以下列舉了幾種常用的集成優(yōu)化模型。 單一神經(jīng)網(wǎng)絡模型具有卓越的數(shù)據(jù)處理能力和學習能力,被廣泛應用在腐蝕領域,當腐蝕數(shù)據(jù)量充足時,其預測性能優(yōu)于很多其他預測模型。當樣本量不足時,結合其他算法模型的集成模型在很大程度上提高了預測的準確性,解決了因數(shù)據(jù)量小而出現(xiàn)的過擬合等問題。 劉威等將神經(jīng)網(wǎng)絡與灰色理論相結合,形成灰色-神經(jīng)網(wǎng)絡模型進行腐蝕預測;凌曉等選擇用遺傳算法來優(yōu)化BPNN模型;王金秋等提出了粗糙集-BP神經(jīng)網(wǎng)絡預測模型;肖斌等提出了一種改進的粒子群算法優(yōu)化的神經(jīng)網(wǎng)絡算法(IPSO-BPNN),這些算法結果證明優(yōu)化后的結果比單一模型結果要更加精確。 SVM是一種能在小樣本條件下進行預測的方法,為了進行更準確地預測,駱正山等基于灰色向量機來建立管道腐蝕預測模型;李響等通過遺傳算法改進SVM模型來進行海洋環(huán)境腐蝕預測,有效降低了預測誤差;SONG等在研究車輛船舶運行條件下碳鋼動態(tài)腐蝕時,構建遺傳算法優(yōu)化支持向量回歸模型(GA-SVR)、遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡模型(GA-BPNN)、未優(yōu)化SVR和未優(yōu)化BPNN4個模型,預測碳鋼在動態(tài)環(huán)境中的腐蝕速率,最終結果表明GA-SVR的均方根誤差跟平均相對誤差最小;LU等提出了利用3D坐標量化數(shù)字參數(shù)來描述生銹鋼筋的橫截面形態(tài),并且建立了粒子群優(yōu)化支持向量機模型(PSO-SVM)和網(wǎng)格搜索支持向量機模型(GS-SVM)兩種優(yōu)化模型來進行鋼的截面腐蝕率預測,兩種腐蝕預測模型的預測結果都比較準確,最后相比之下,PSO-SVM的精度要優(yōu)于GS-SVM。 隨機森林本來就是集成算法的一種,相較于本身單一的決策樹模型,隨機森林模型優(yōu)點更多,更加適用于腐蝕速率預測模型的建立,也是近年來的研究熱點。ZHI等提出了一種新的深度結構模型,全連接級聯(lián)動態(tài)集成選擇森林算法(DCGF-WKNN),用來實現(xiàn)腐蝕建模數(shù)據(jù)預測,與單一算法模型人工神經(jīng)網(wǎng)絡(ANN)、支持向量回歸(SVR)等相比,該方法能夠獲得最佳的預測效果。
3
結論與展望 ? 目前,人們對腐蝕領域的數(shù)據(jù)挖掘方法進行了廣泛的研究,揭示了隱藏于數(shù)據(jù)背后的腐蝕信息、建立了腐蝕損傷預測模型,但將其成熟應用于指導工程實踐還需要開展更深入的研究以及更長時間的檢驗。 (1) 在腐蝕數(shù)據(jù)挖掘研究的早期,受腐蝕數(shù)據(jù)采集技術的限制,數(shù)據(jù)樣本有限,相關研究主要是對數(shù)據(jù)進行回歸、擬合,揭示環(huán)境因素影響腐蝕的規(guī)律,構建劑量響應方程用于腐蝕預測。隨著腐蝕數(shù)據(jù)的持續(xù)性積累與人工智能技術的興起,部分機器學習的方法如支持向量機、人工神經(jīng)網(wǎng)絡、隨機森林等技術被移植應用于腐蝕數(shù)據(jù)挖掘并取得了較好的效果,但絕大多數(shù)模型對應用邊界具有嚴格的限定,泛化能力較差,限制了其應用。 (2) 隨著近些年信息技術的快速發(fā)展,腐蝕在線監(jiān)測設備在許多領域得到應用,腐蝕數(shù)據(jù)實現(xiàn)了連續(xù)性采集以及數(shù)據(jù)、圖像、視頻等多維表現(xiàn),腐蝕數(shù)據(jù)是數(shù)量極其龐大且具有時序性的,腐蝕數(shù)據(jù)挖掘更適于采用大數(shù)據(jù)分析和處理的方法,在后續(xù)的研究中,多種算法的集成應用將更有利于擴展模型的使用邊界、提高分析或模擬結果的準確性。與此同時,與連續(xù)性采集的腐蝕數(shù)據(jù)不相匹配的是部分影響腐蝕進程的關鍵環(huán)境特征參數(shù)的在線監(jiān)測技術還有待于進一步研究開發(fā),以保障數(shù)據(jù)挖掘過程中腐蝕數(shù)據(jù)關鍵數(shù)據(jù)項的完整性。
免責聲明:本網(wǎng)站所轉載的文字、圖片與視頻資料版權歸原創(chuàng)作者所有,如果涉及侵權,請第一時間聯(lián)系本網(wǎng)刪除。
-
標簽: 腐蝕, 腐蝕監(jiān)測, 腐蝕數(shù)據(jù), 數(shù)據(jù)處理
相關文章

官方微信
《腐蝕與防護網(wǎng)電子期刊》征訂啟事
- 投稿聯(lián)系:編輯部
- 電話:010-62316606-806
- 郵箱:fsfhzy666@163.com
- 腐蝕與防護網(wǎng)官方QQ群:140808414
文章推薦
點擊排行
PPT新聞

“海洋金屬”——鈦合金在艦船的
點擊數(shù):8398

腐蝕與“海上絲綢之路”
點擊數(shù):6744